How to Implement Retrieval-Augmented Generation (RAG)?

Retrieval Augmented Generation (RAG) is changing how businesses interact with large-scale information and deliver real-time, contextual answers. If you're a decision-maker or innovator looking to enhance customer experiences, automate workflows, or power smarter search tools — RAG might be your secret weapon.
This human-friendly guide by Redblox Technologies dives deep into the world of RAG. Whether you're in healthcare, e-commerce, customer service, or finance — we'll show you how RAG can fit your unique business needs.
What is Retrieval-Augmented Generation (RAG)?
RAG is a powerful AI framework that combines two core techniques:
- Retrieval: Fetch relevant data/documents from external sources like databases, APIs, or document libraries.
- Generation: Use a Large Language Model (LLM) like GPT-4 to generate human-like responses using the retrieved content.
Think of RAG as a smart librarian paired with a skilled writer — first finding the right information, then presenting it in a natural, useful way.
Unlike traditional AI that generates answers based only on training data, RAG provides real-time, fact-based, and context-aware responses.
Why RAG Matters in 2025 and Beyond
The AI market is expected to hit $1.8 trillion by 2030, with RAG models forming the core of enterprise solutions. Businesses need:
- Up-to-date information
- Contextual customer support
- Reduced hallucinations in AI
- Faster knowledge discovery
That’s exactly where RAG steps in — bridging static models with dynamic, real-world content.
Steps to create a multilingual chatbot using AI
Key Benefits of RAG for Businesses
- Improved Accuracy: Minimized AI hallucination by grounding answers in real data
- Faster Knowledge Discovery: No more sifting through endless documents
- Real-Time Updates: Fetch the latest from APIs, databases, or CMS
- Cost-Effective:Use smaller, fine-tuned models + retrieval, rather than retraining large LLMs
- Scalable Across Domains: Healthcare, fintech, legal, support, and more
- Multi-Language Support: Works well with global datasets
How RAG Works: The Architecture Explained
Step 1: Query Input
User inputs a query (like "What is the latest GDPR update?").
Step 2: Document Retrieval
RAG uses a vector database (e.g., FAISS, Pinecone) to retrieve semantically similar documents from a knowledge base.
Step 3: Generation
An LLM (e.g., OpenAI GPT-4, Anthropic Claude) uses the retrieved data to generate a response
Step 4: Output
The final answer is delivered — grounded, coherent, and contextually correct.
Step-by-Step Guide to Implement RAG
1. Define Your Use Case
Start with a specific goal: product support, internal knowledge base, document search, etc.
2. Prepare Knowledge Base
Clean and structure your PDFs, web pages, CSVs, or API outputs.
3. Embed Your Documents
Use vector embeddings (OpenAI, HuggingFace) to turn content into searchable vector
4. Set Up Vector Store
Choose FAISS, Pinecone, Weaviate, or Qdrant for storing embedded documents.
5. Build Retrieval Pipeline
Set up semantic search to retrieve top-k relevant chunks.
6. Connect to LLM
Feed the retrieved results to an LLM using LangChain or similar frameworks.
7. Deploy and Test
Host on AWS, Azure, or private cloud and test across edge cases.
8. Monitor & Improve
Track user queries, feedback loops, and relevancy scores.
How AI is transforming customer relationship management
Use Cases of RAG Across Industries
- Healthcare: Drug information, diagnosis support, clinical documentation
- E-commerce: Product recommendations, catalog search, order FAQs
- Legal: Case document search, regulation summaries
- Education: Personalized tutoring, knowledge portals
- Finance: Fraud detection assistance, regulation alerts
- HR: Policy Q&A, onboarding support
RAG in Action: Real-World Stats & Adoption Trends
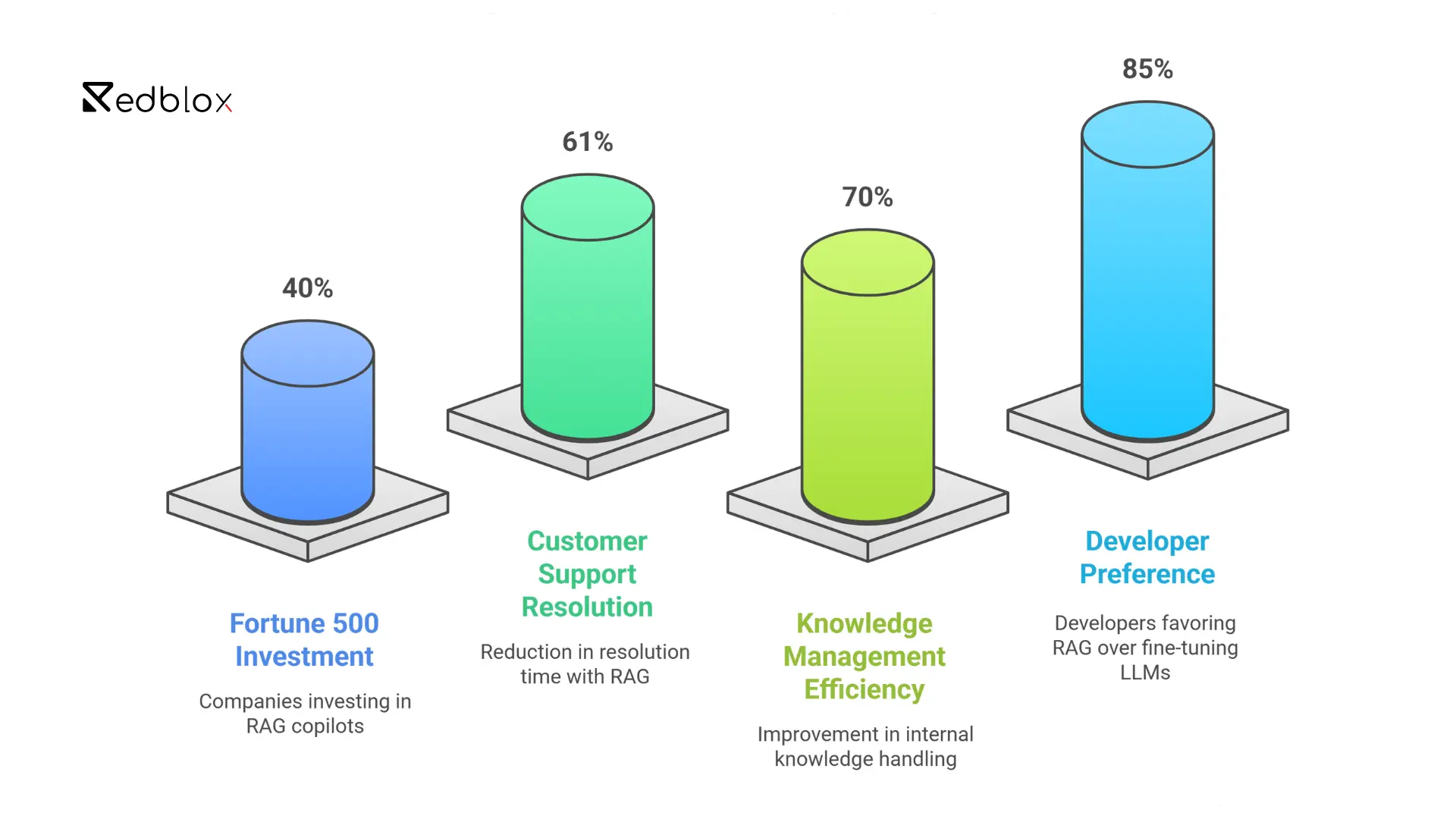
RAG vs Traditional Chatbots and LLMs

Technologies and Tools Used in RAG
- LLMs: GPT-4, Claude, Mistral
- Embeddings: OpenAI, Cohere, HuggingFace Transformers
- Vector DBs: Pinecone, FAISS, Qdrant, Weaviate
- Frameworks: LangChain, LlamaIndex, Haystack
- Deployment: AWS Lambda, Sagemaker, Azure Functions, GCP
Challenges and Considerations
- Data privacy in vector stores
- Context window limits of LLMs
- Prompt engineering complexity
- Latency in retrieval + generation
- High-quality embedding choice
How Redblox Technologies Helps You Implement RAG
At Redblox Technologies, we specialize in building secure, scalable, and cost-effective RAG architectures tailored to your industry. Our team can:
- Audit and prepare your knowledge base
- Set up embedding and vector pipelines
- Connect your system to the latest LLMs (OpenAI, Claude, Mistral)
- Build custom RAG-powered chatbots, search engines, and assistants
- Deploy RAG workflows on AWS, Azure, or your preferred stack
Ready to transform your operations with Retrieval Augmented Generation?
Contact Redblox Technologies today to schedule your free AI consultation.
Final Thoughts and Next Steps
RAG is no longer a futuristic concept. It's already revolutionizing how businesses manage and retrieve knowledge in real time. From smarter chatbots to intelligent search tools, the applications are endless.
With the right strategy, RAG can help you:
- Deliver better customer experiences
- Reduce operational costs
- Stay ahead of competitors
The future of business intelligence is here — and it’s retrieval-augmented.
FAQs
Q1. How is RAG different from traditional AI models?
Traditional models rely on static knowledge. RAG brings in real-time data, grounding answers in current context and reducing hallucinations.
Q2. Is RAG suitable for small businesses?
Absolutely! RAG can be scaled to suit small teams with specific knowledge bases. It's more cost-effective than retraining large models.
Q3. Can I integrate RAG with my existing CRM or CMS?
Yes. With APIs and tools like LangChain, RAG can be integrated with CRMs like Salesforce, HubSpot, and CMSs like WordPress.
Q4. What are the costs involved in implementing RAG?
Costs depend on data size, vector storage, API calls to LLMs, and infrastructure. Redblox offers flexible plans based on business needs.
Q5. How long does it take to deploy a RAG-based solution?
Typically between 2 to 6 weeks, depending on complexity. Redblox Technologies offers rapid prototypes within days.
Fill your details below and get in touch with our domain experts
Start a conversation
+91 7550051204
contact@redblox.io
Book 1:1 Meeting with Redblox
@redblox_technologies